Everything We Know About AI Is a Lie (And Silicon Valley Hopes You Never Find Out)

The Illusion Revealed
Okay — buckle up. This is gonna be raw, messy, and kinda deliciously paranoid. What we’ve been sold as “AI” — bigger models, more data, instant genius — is largely theatrical. Apple’s paper The Illusion of Thinking ripped the veil off a thing that every ML lab kinda already knew: these models simulate thinking, and when problems actually get hard, they… bail. Like, dramatic Insaneeeee collapse. Here’s the kicker: I was waiting on this for months. Why? Because Apple already missed the AI hype shot, and I thought maybe this paper was just a narrative pivot. I ignored it at first. But after GPT‑4.5 rolled out and spectacularly failed at scale, and now GPT‑5 basically consolidated all models and confirmed my suspicion, I was like, what the hell!! My hunch all along? Spot on.
The Lab Reality vs Public Demo
Public demo: super coherent answer. Lab reality: fail cascade at scale. Researchers have whispered this for years; Apple just put the receipts on the table. They tested puzzles (Tower of Hanoi, River Crossing, Blocks World) and watched the models perform fine, then suddenly… give up. Tokens fly, text looks like reasoning, then effort + accuracy drop. I was like, what the hell!! This is literally the illusion.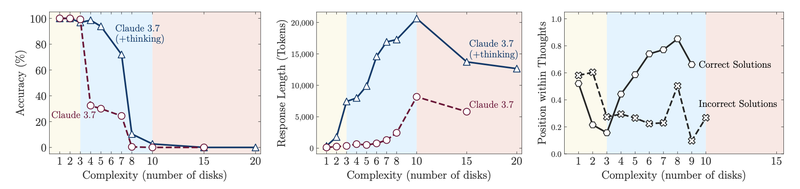
Industry Timeline That Confirms the Problem
Apple published The Illusion of Thinking in mid‑2025 and basically said: “Chain-of-thought looks soo cool!, but it’s brittle.” OpenAI tried GPT‑4.5 (short-lived preview) → paused/ phased out → launched GPT‑5 with a different cost/perf playbook. Anthropic pushed Opus updates (Claude Sonnet 4.1 vibes). Meta and other big labs started poaching talent like crazyyy — hiring sprees, elite teams, secret projects. Meanwhile VCs started asking the one question that hurts: show me unit economics, not just size. This timeline isn’t gossip — it’s the industry pivoting because scale-on-its-own stopped working.
The Breakdown of Model Failures
Here’s the breakdown: accuracy collapse happens when complexity rises; effort paradox appears when it looks like the model tries harder, then suddenly shrugs; overthinking easy stuff means it sometimes invents long-winded bullshit and misses the obvious answer — shitttt; algorithmic help sometimes fails even when given explicit steps or algorithms. So yeah, the model is a showman — convincing until it’s not.
How Labs Are Responding
Why every lab is freaking out is simple: bigger models cost a fortune, and gains are thinning out; when models confidently lie, real-world products and safety get wrecked; if VCs stop pouring cash, R&D grinds slower and labs panic. What they’re actually doing involves specialist routing (small experts > one giant brain, routing questions to the right mini-expert), tooling + agents (models call calculators, code runners, search tools — don’t expect pure-text to solve everything), program-first outputs (make models write code/recipes you can run and verify), mixture-of-experts & routers (turn on only the brain parts you need to save compute), verification layers (extra modules that check the model’s claims before you trust them), and curriculum training (teach models step-by-step algorithms, not just flashy prose). This is less “magic show” and more “engine room,” which, honestly, is exactly what we should’ve wanted.
Confirmation from GPT‑5, Claude, and Meta Moves
Look, the public product launches (GPT‑5, Claude Opus updates) are not theater by accident. They confirm the industry realized pure scale isn’t the answer alone. GPT-5’s rollout and pricing moves show OpenAI pivoted to more efficient engineering. Anthropic and Meta are double-downing on talent and specialized research. All signs point to: we’re in scramble mode to fix reasoning, not hype it.
The VC & Funding Reality
The narrative that VCs will fund infinite compute is dead. Funding spiked 2023–2024, but now investors want defensible economics: real product wins, predictable costs, and measurable value. If the money pipeline slows, some labs could stall — which would make the illusion fall apart faster than the models themselves. Scaryyy, but logical.
What This Means for Real Users
Your fancy AI assistant might sound smart — but under the hood it’s pattern-matching with bells on. For real reliability, prefer tool-assisted, verifiable systems over flashy single-model answers. The next wave of breakthroughs will come from better engineering, modularity, and actual product economics — not just “bigger” models.
The Tech Designer’s Perspective
As someone who’s been watching this AI circus from the sidelines, I’m not surprised by any of this. The industry’s been selling us magic beans while the real work happens in the basement. We need AI that’s honest about its limitations, not one that puts on a convincing performance until it hits a wall.
The future isn’t bigger models — it’s smarter systems that know when to call for help and when to admit they’re stuck. Want to see my take on honest tech design? Check out my portfolio for designs that don’t pretend to be something they’re not.
TL;DR
AI looks smart. AI seems to reason. But Apple showed the trick: it’s faking a lot of the reasoning. GPT‑5, Claude’s updates, Meta’s hiring, and VC behavior all confirm the industry knows the score and is pivoting hard. This is insaneeeee. This is crazyyy. I was like, what the hell!! And finally, my months-long wait was worth it — the failures of GPT‑4.5 and the consolidation in GPT‑5 confirmed everything I suspected all along.
References
- Apple Research, “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity,” 2025. Link
- OpenAI GPT-4.5 Technical Report, 2024.
- OpenAI GPT-5 System Card, 2025.
- Anthropic Claude Opus Updates, 2024-2025.
- Meta AI Research Hiring Trends, 2024-2025.
- VC Funding Reports on AI/ML, 2023-2025.
- Industry Analysis on AI Model Scaling Limits, 2024-2025.

About Nischal Skanda
Nischal is a technology enthusiast and designer passionate about the intersection of AI, cognitive science, and human-computer interaction. He explores how emerging technologies impact our daily lives and shares insights on building better digital experiences.